This article is for users of Travis CI services interested in moving their OCaml, opam or BSD Owl projects to the new container-based infrastructure provided by Travis CI.
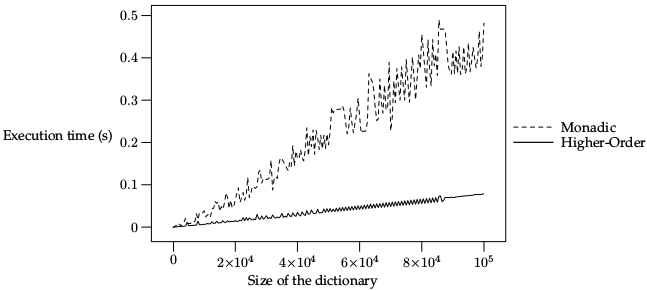
Travis, a continuous-integration service, introduced a new container-based infrastructure, promising more speed and reactivity than the old virtual-machine-based infrastructure, which is now deemed deprecated. Users willing to take the move to the new infrastructure are facing a major obstacle: the container-based infrastructure does not support the sudo command, which, in cascade, implies that the Travis users are not able any-more to install packages from random package sources. These dependencies now need to be installed from source until you arrange so that a repository containing these dependencies has been white-listed.
The script
The continuous integration script is everything but fancy, it setups opam to target the compiler announced by TRAVIS_OCAML_VERSION and runs the traditional
Travis, a continuous-integration service, introduced a new container-based infrastructure, promising more speed and reactivity than the old virtual-machine-based infrastructure, which is now deemed deprecated. Users willing to take the move to the new infrastructure are facing a major obstacle: the container-based infrastructure does not support the sudo command, which, in cascade, implies that the Travis users are not able any-more to install packages from random package sources. These dependencies now need to be installed from source until you arrange so that a repository containing these dependencies has been white-listed.
The script
anvil_travisci_autoinstall.sh distributed with anvil will ease this operation
for OCaml, opam and BSD Owl users!Setting up Travis
We set up Travis to take advantage of its cache, which is not optional since a compilation matrices involving the three latest OCaml compilers needs about 15 minutes setup. For the purpose of the discussion, we consider the example of mixture, an OCaml library implementing common mixins. Let us walk through its.travis.yml file:language: c
sudo: false
addons:
apt:
sources:
- avsm
packages:
- ocaml
- opam
- ocaml-native-compilers
install: sh -ex ./Library/Ancillary/autoinstall bmake bsdowl opam
cache:
directories:
- ${HOME}/.local
- ${HOME}/.opam
script: sh -ex ./Library/Ancillary/travisci
env:
- TRAVIS_OCAML_VERSION=4.00.1
- TRAVIS_OCAML_VERSION=4.01.0
- TRAVIS_OCAML_VERSION=4.02.3language, sudo and addons constitute the
typical prelude of OCaml projects. The script
./Library/Ancillary/autoinstall installs dependencies from sources
and initialises opam. The sources are installed to
${HOME}/.local and opam files are stored in ${HOME}/.opam,
caching these files allows us to skip completely this step in case of
a cache hit. We present the autoinstall script later, but right now
we want to take a look at the last lines of .travis.yml: it defines
the actual continuous integration script and a build environement
matrix.The continuous integration script is everything but fancy, it setups opam to target the compiler announced by TRAVIS_OCAML_VERSION and runs the traditional
autoconf; ./configure; bmake all combo:INSTALL_PREFIX="${HOME}/.local"
eval $(opam config env)
autoconf
./configure --prefix="${INSTALL_PREFIX}"
bmake -I "${INSTALL_PREFIX}/share/bsdowl" allThe autoinstall script
The script installing dependencies from sources actually delegates the job toanvil_travisci_autoinstall.sh. Theoretically, this script
could be bundled in the distribution instead of being downloaded, but
doing so eases updates. The autoinstall script is:: ${local:=${HOME}/.local}
: ${srcdir:=${HOME}/.local/sources}
if [ -f "${local}/.anvil_autoinstall_cached" ]; then exit 0; fi
git clone 'https://github.com/michipili/anvil' "${srcdir}/anvil"
/bin/sh -ex "${srcdir}/anvil/subr/anvil_travisci_autoinstall.sh" "$@"\
&& touch "${local}/.anvil_autoinstall_cached"autoinstall
script supports three arguments, bmake, bsdowl and opam
requiring the setup of the corresponding packages. When setting up
opam the file .travis.opam is read to find out which compilers and
packages need to be installed:compiler:
- 4.00.1
- 4.01.0
- 4.02.3
repository:
- ocamlfind
git:
- https://github.com/michipili/broken.git.travis.yml
but it is converted to a tabular format with sed so that
imaginative formatting is discouraged. There is two ways to specify a
dependant package: either by reffering to a name in the official
repository, or directly with a git repository supporting opam
pinning.